
Все, что вы хотели найти про дубли страниц на сайте и дублирование контента. Узнайте 7 методов, чтобы проверить, найти и убрать все, что мешает развитию.
Неважно какой движок у вашего сайта: Bitrix, WordPress, Joomla, Opencart… Проверка сайта на дубли страниц может выявить эту проблему и её придется срочно решать.
Дублирование контента, равно как и дубли страниц на сайте, является большой темой в области SEO. Когда мы говорим об этом, то подразумеваем наказание от поисковых систем.
Этот потенциальный побочный эффект от дублирования контента едва ли не самый важный. Даже с учетом того, что Google по сути почти никогда не штрафует сайты за дублирование информации.
Наиболее вероятные проблемы для SEO из-за дублей:
Потраченный краулинговый бюджет.
Если дублирование контента происходит внутри веб-ресурса, гарантируется, что вы потратите часть краулингового бюджета (выделенного лимита на количество индексируемых за один заход страниц) при обходе дублей страниц поисковым роботом. Это означает, что важные страницы будут индексироваться менее часто.
Разбавление ссылочного веса.
Как для внешнего, так и для внутреннего дублирования контента разбавление ссылочного веса является самым большим недостатком для SEO. Со временем оба URL-адреса могут получить обратные ссылки. Если на них отсутствуют канонические ссылки (или 301 редирект), указывающие на исходный документ, вес от ссылок распределится между обоими URL.
Только один вариант получит место в поиске по ключевой фразе.
Когда поисковик найдет дубли страниц на сайте, то обычно он выберет только одну в ответ на конкретный поисковый запрос. И нет никакой гарантии, что это будет именно та, которую вы продвигаете.
Любые подобные сценарии можно избежать, если вы знаете, как найти дубли страниц на сайте и убрать их. В этой статье представлено 7 видов дублирования контента и решение по каждому случаю.
Стоит заметить, что дубли контента могут быть не только у вас на сайте. Ваш текст могут просто украсть. Начнем разбор с этого варианта.
1 Копирование контента
Скопированное содержание в основном является неоригинальной частью контента на сайте, который был скопирован с другого сайта без разрешения. Как я уже говорилось ранее, Google не всегда может точно определить, какая часть является оригинальной. Так что задачей владельца сайта является поиск фактов копирования контента и принятие мер, если обнаружится факт кражи контента.
Увы, это не всегда легко и просто. Но иногда может помочь маленькая хитрость.
Отслеживайте сохранение уникальности ваших документов (если у вас есть блог, желательно это контролировать) с помощью каких-либо сервисов (например, text.ru) или программ. Скопируйте текст своей статьи и запустите проверку уникальности.
Конечно, если сайт содержит сотни статей, то проверка займет много времени. Поэтому я установил на данный сайт комментарии «Hypercomments» и включил функцию фиксации цитирования. Каждый раз, как кто-то скопирует кусок текста, он появляется во вкладке цитаты. Мне сразу видно, что был скопирован весь текст такой-то статьи. Это повод проверить её уникальность через некоторое время.
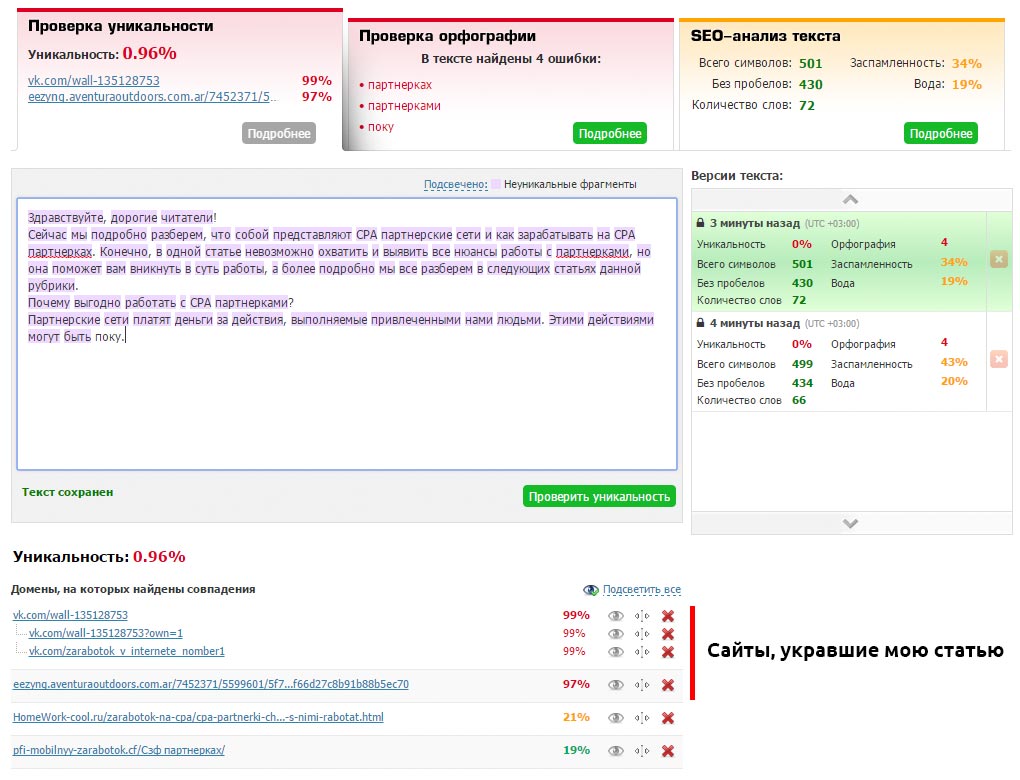
Таким образом вы найдет все сайты, которые содержат текст полностью или частично взятый с вашего сайта. В таком случае необходимо первым делом обратиться к веб-мастеру с просьбой удалить позаимствованный контент (или поставить каноническую ссылку, если это для вашего бизнеса работает и его сайт не слишком плохой в плане SEO). Если консенсус не будет достигнут, вы можете сообщить о копии в Google: отчет о нарушении авторских прав.
2 Синдикация контента
Синдикация – это переиздание содержания на другом сайте с разрешения автора оригинального произведения. И хотя она является законным способом получения вашего контента для привлечения новой аудитории, важно установить рекомендации для издателей, чтобы синдикация не превратилась в проблемы для SEO.
В идеале, издатель должен использовать канонический тег на статью, чтобы указать, что ваш сайт является первоисточником. Другой вариант заключается в применении тега noindex к синдицированному контенту.
Вариант 1: <link rel=»canonical» href=»http://site.ru/original-content» />
Вариант 2: <div rel=»noindex»>Синдицированный контент</div>
Всегда проверяйте это вручную каждый раз, когда разрешаете дублирование вашего контента на других сайтах.
3 HTTP и HTTPS протоколы
Одной из наиболее распространенных внутренних причин дублирования страниц на сайте является одновременная работа сайта по протоколам HTTP и HTTPS. Эта проблема возникает, когда перевод сайта на HTTPS реализован с нарушением инструкции, которую можно прочитать по ссылке. Две распространенные причины:
Отдельные страницы сайта на протоколе HTTPS используют относительные URL
Это часто актуально, если использовать защитный протокол только для некоторых страниц (регистрация/авторизация пользователя и корзина покупок), а для всех остальных – стандартный HTTP. Важно иметь в виду, что защищенные страницы могут иметь внутренние ссылки с относительными URL-адресами, а не абсолютными:
Абсолютный: https://www.homework-cool.ru/category/product/
Относительный: /product/
Относительные URL не содержат информацию о протоколе. Вместо этого они используют тот же самый протокол, что и родительская страница, на которой они расположены. Если поисковый бот найдет такую внутреннюю ссылку и решит следовать по ней, то перейдет по ссылке с HTTPS. Затем он может продолжить сканирование, пройдя по нескольким относительным внутренним ссылкам, а может даже просканировать весь сайт с защитным протоколом. Таким образом в индекс попадут две совершенно одинаковые версии ресурса.
В этом случае необходимо использовать абсолютные URL-адреса вместо относительных для внутренних ссылок. Если боту уже удалось найти дубли страниц на сайте, и они отобразились в панели вебмастера в Яндексе или Google, то установите 301 редирект, перенаправляя защищенные страницы на правильную версию с HTTP. Это будет лучшим решением.
Вы полностью перевели сайт на HTTPS, но HTTP версия все еще доступна
Это может произойти, если есть обратные ссылки с других сайтов, указывающие на HTTP версию, или некоторые из внутренних ссылок на вашем ресурсе по-прежнему содержат старый протокол.
Чтобы избежать разбавления ссылочного веса и траты краулингового бюджета используйте 301 редирект с HTTP и убедитесь, что все внутренние ссылки указаны с помощью относительных URL-адресов.
Чтобы быстро проверить дубли страниц на сайте из-за HTTP/HTTPS протокола, нужно проконтролировать работу настроенных редиректов.
4 Страницы с WWW и без WWW
Одна из самых старых причин для появления дублей страниц на сайте, когда доступны версии с WWW и без WWW. Как и HTTPS, эта проблема обычно решается за счет включения 301 редиректа. Также необходимо указать ваш предпочтительный домен в панели вебмастера Google.
Чтобы проверить дубли страниц на сайте из-за префикса WWW, так же редирект должен корректно работать.
5 Динамически генерируемые параметры URL
Динамически генерируемые параметры часто используются для хранения определенной информации о пользователях (например, идентификаторы сеансов) или для отображения несколько иной версии той же страницы (например, сортировка или корректировка фильтра продукции, поиск информации на сайте, оставление комментариев). Это приводит к тому, что URL-адреса выглядят следующим образом:
URL 1: https:///homework-cool.ru/position.html?newuser=true
URL 2: https:///homework-cool.ru/position.html?older=desc
Несмотря на то, что эти страницы будут содержать дубли контента (или очень похожую информацию), для поисковых роботов это повод их проиндексировать. Часто динамические параметры создают не две, а десятки различных версий страниц, которые могут привести к значительному количеству напрасно проиндексированных документов.
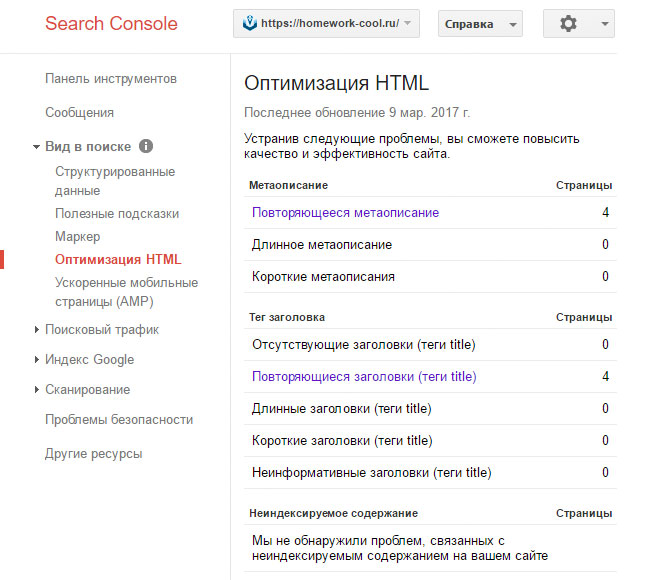
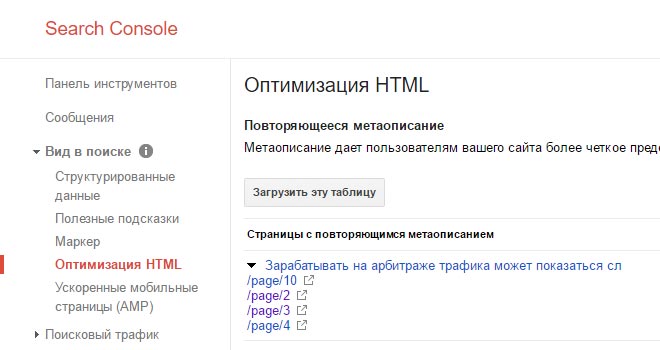
Найти дубли страниц на сайте можно с помощью панели вебмастера Google в разделе «Вид в поиске — Оптимизация HTML»
Яндекс Вебмастер покажет их в «Индексирование – Страницы в поиске»
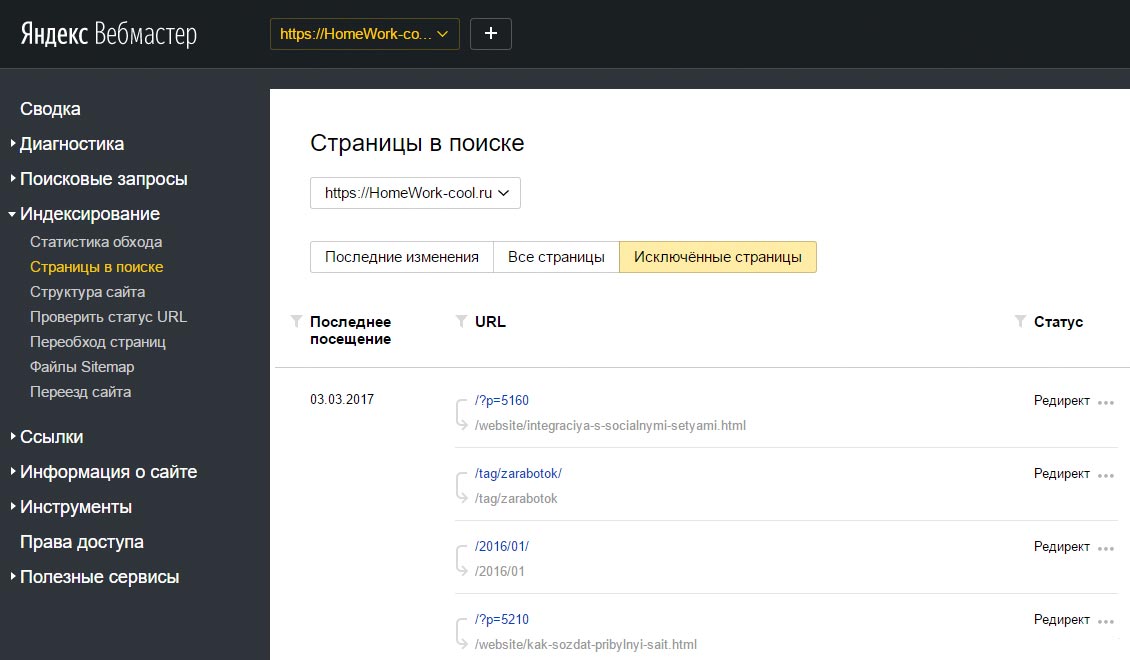
Для конкретного случая в индексе Google находятся четыре страницы пагинации с одинаковым метаописанием. А скриншот из Яндекса наглядно показывает, что на все «лишние» атрибуты в ссылках настроен редирект, включая теги.
Еще можно прямо в поисковике ввести в строку:
site:domen.ru -site:domen.ru/&
Таким образом можно найти частичные дубли страниц на сайте и малоинформативные документы, находящиеся в индексе Google.
Если вы найдете такие страницы на вашем сайте, убедитесь, что вы правильно классифицируете параметры URL в панели вебмастера Google. Таким образом вы расскажите Google, какие из параметров должны быть проигнорированы во время обхода.
6 Подобное содержание
Когда люди говорят про дублирование контента, они подразумевают совершенно идентичное содержание. Тем не менее, кусочки аналогичного содержания так же попадают под определение дублирования контента на сайте от Google:
«Если у вас есть много похожих документов, рассмотрите вопрос о расширении каждого из них или консолидации в одну страницу. Например, если у вас есть туристический сайт с отдельными страницами для двух городов, но информация на них одинакова, вы можете либо соединить страницы в одну о двух городах или добавить уникальное содержание о каждом городе»
Такие проблемы могут часто возникать с сайтами электронной коммерции. Описания для аналогичных продуктов могут отличаться только несколькими специфичными параметрами. Чтобы справиться с этим, попробуйте сделать ваши страницы продуктов разнообразными во всех областях. Помимо описания отзывы о продукте являются отличным способом для достижения этой цели.
На блогах аналогичные вопросы могут возникнуть, когда вы берете старую часть контента, добавите некоторые обновления и опубликуете это в новый пост. В этом случае использование канонической ссылки (или 301 редиректа) на оригинальный пост является лучшим решением.
7 Страницы версий для печати
Если страницы вашего сайта имеют версии для печати, доступные через отдельные URL-адреса, то Google легко найдет их и проиндексирует через внутренние ссылки. Очевидно, что содержание оригинальной статьи и её версии для печати будет идентичным – таким образом опять тратится лимит индексируемых за один заход страниц.
Если вы действительно предлагаете печатать чистые и специально отформатированные документы вашим посетителям, то лучше закрыть их от поисковых роботов с помощью тега noindex. Если все они хранятся в одном каталоге, таком как https://homework-cool.ru/news/print/, вы можете даже добавить правило Disallow для всего каталога в файле robots.txt.
Disallow: /news/print
Подведем итоги
Дублирование контента и скрытые дубли страниц на сайте могут обернуться головной болью для оптимизаторов, так как это приводит к потере ссылочного веса, трате краулингового бюджета, медленной индексации новых страниц.
Помните, что вашими лучшими инструментами для борьбы с этой проблемой являются канонические ссылки, 301 редирект и robots.txt. Не забывайте периодически проверять и обновлять контент вашего сайта с целью улучшения индексации и ранжирования в поисковых системах.
Какие случаи дублей страниц вы находили на своем сайте, какие методы используете, чтобы предотвратить их появление? Я с нетерпением жду ваших мыслей и вопросов в комментариях.